Similarity
The concept of similarity is essential to synthetic data. The source data has statistical properties, such as distributions of values. How well are these properties and distributions mirrored in the safe synthetic data?
Hazy measures similarity for a single column, pair of columns and a matrix of columns:
- single column: marginal distribution
- matrix of columns: mutual information
- pair of tables: cross-table mutual information
- sequential discriminator: sequential discriminator
Marginal distribution¶
This metric evaluates how well the distribution of each individual column is preserved. To do so, the source and synthetic datasets are binned using the same bins and binning strategy. A score is then computed by calculating the overlap of the two histograms as the sum of the minimum over each bin.
Use cases¶
This metric is to be used if the statistics within each column are to be preserved. Assuming there is a good overlap between the synthetic and source column, then most general statistics such as mean, median, 90th percentile, and so on, should be similar. Typically this kind of information can be useful when producing a statistical report focusing on the overall dataset such as an age or gender distribution analysis in a customer base.
Interpretation¶

The amount of intersection between the source and synthetic histograms indicate how well the statistical properties of the column has been captured.
| Quality interpretation guide | ||||
|---|---|---|---|---|
| 0% – 30% | 30% – 60% | 60% – 80% | 80% – 90% | 90% – 100% |
|
|
|
|
|
|
Troubleshooting¶
If this metric shows poor results for one or several columns, you can try to improve the results by doing one or several of the following:
- Increase n_bins
- Increase max_cat
- Increase n_parents
- Increase sample_parents
- Select a more complex classifier :
DecisionTree,RandomForest,LGBM
Mutual information¶
Histogram similarity fails to capture the dependencies between different columns in the data. For that purpose we use the concept of mutual information that measures the co-dependencies, or correlations if the data is numeric, between all pairs of variables. Quantifying this information is an abstract but very powerful concept that allows us to understand the relationship between variables.
Hazy’s score for mutual information is the average of the ratio between the mutual information on all pairs of variables in source data and the synthetic data :
where is the Jaccard similarity defined as .
Use cases¶
It is recommended to use this metric for more advanced use-cases where cross column statistics and information must be preserved. This is typically this case for analytics, Machine Learning or Reporting use-cases. A typical example of when this metric is useful is when a user is interested in verifying the relationship between specific columns (such as “income” and “age”) is preserved. This relationship can then be leveraged in reporting, analysis or a machine learning algorithm.
Interpretation¶
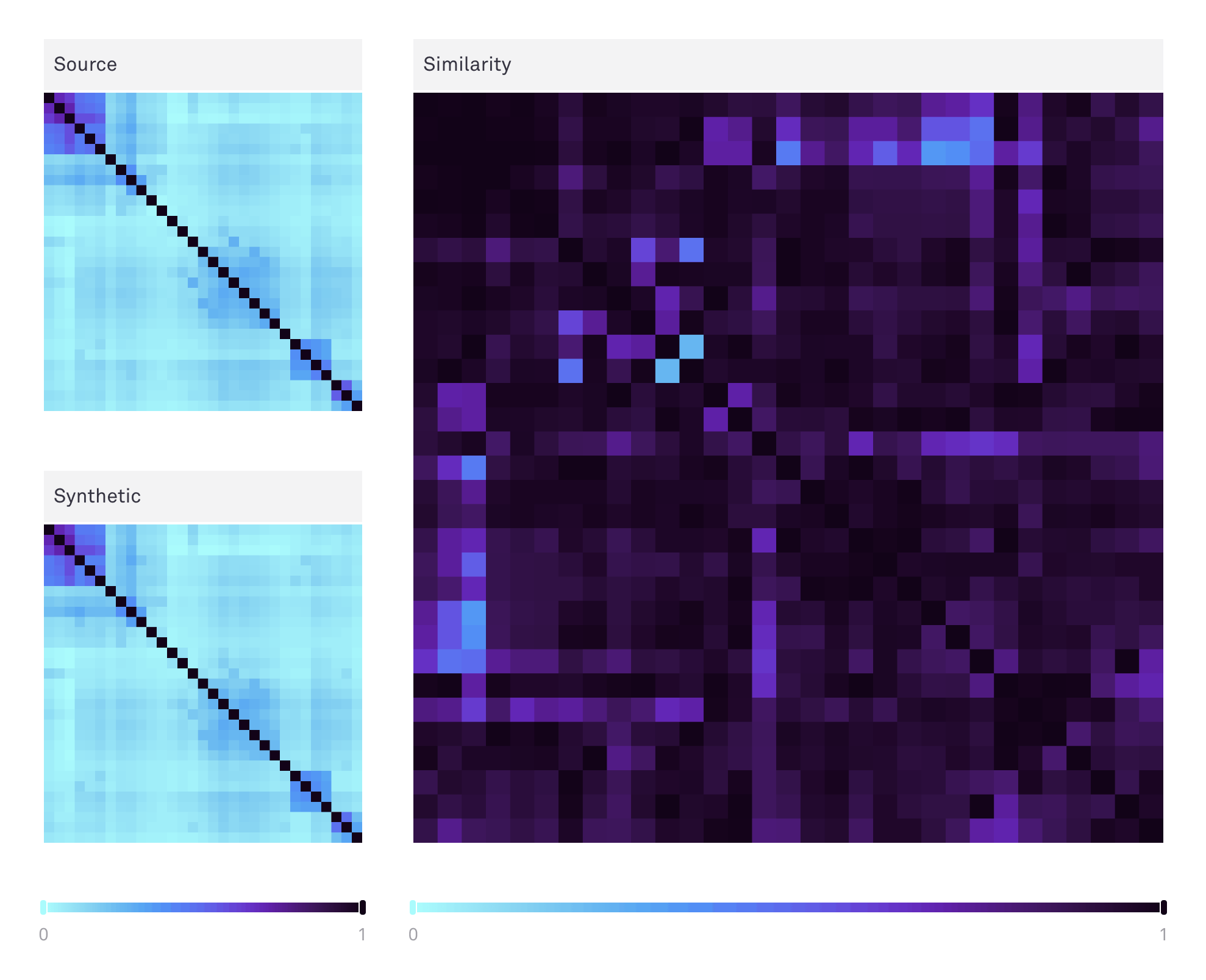
The Hazy UI displays a heatmap of the mutual information matrix for the source data, and the synthetic. To aid a visual comparison of the two, we use an optimal leaf ordering of the source columns to cluster similarities. The difference between these two matrices is also shown, which is the basis for the final mutual information score. Hovering over any square will indicate the column pair as well as the score in question. You can use the range sliders to increase the contrast on a subsetted range of values, i.e. very low or very high scores.
| Quality interpretation guide | ||||
|---|---|---|---|---|
| 0% – 30% | 30% – 60% | 60% – 80% | 80% – 90% | 90% – 100% |
|
|
|
|
|
|
Troubleshooting¶
If this metric shows poor results for one or several columns, you can try to improve the results by doing one or several of the following:
- Increase n_bins
- Increase max_cat
- Increase n_parents
- Increase sample_parents
- Select a more complex classifier :
DecisionTree,RandomForest,LGBM
Cross-table mutual information¶
This metric is applicable in a multi-table context and captures how well models capture the relations between tables. The metric is identical to the mutual information metric, but for the additional constraint that pairs of columns must be in different tables.
| Quality interpretation guide | ||||
|---|---|---|---|---|
| 0% – 30% | 30% – 60% | 60% – 80% | 80% – 90% | 90% – 100% |
|
|
|
|
|
|
Sequential Discriminator¶
This metrics measure how similar the generated sequential data is by training a classifier or discriminator to identify the source data from the generated synthetic data. In priciple, the worse the synthetic data, the easier it is to distinguish and the higher the accuracy of the discriminator. The score is then computed as the distance between the accuracy score and 0.5 which should be the 'perfect' score if the 2 datasets are indistinguishable.
| Quality interpretation guide | ||||
|---|---|---|---|---|
| 0% – 30% | 30% – 60% | 60% – 80% | 80% – 90% | 90% – 100% |
|
|
|
|
|
|