Sequential data
This section explains what sequential data is.
What is sequential data and why is it harder to model?¶
Sequential data is any type of data with dependencies between rows. Examples can be:
- Time-series (weather conditions of a specific location, stock market prices, and so on).
- Bank transactions over a specific period.
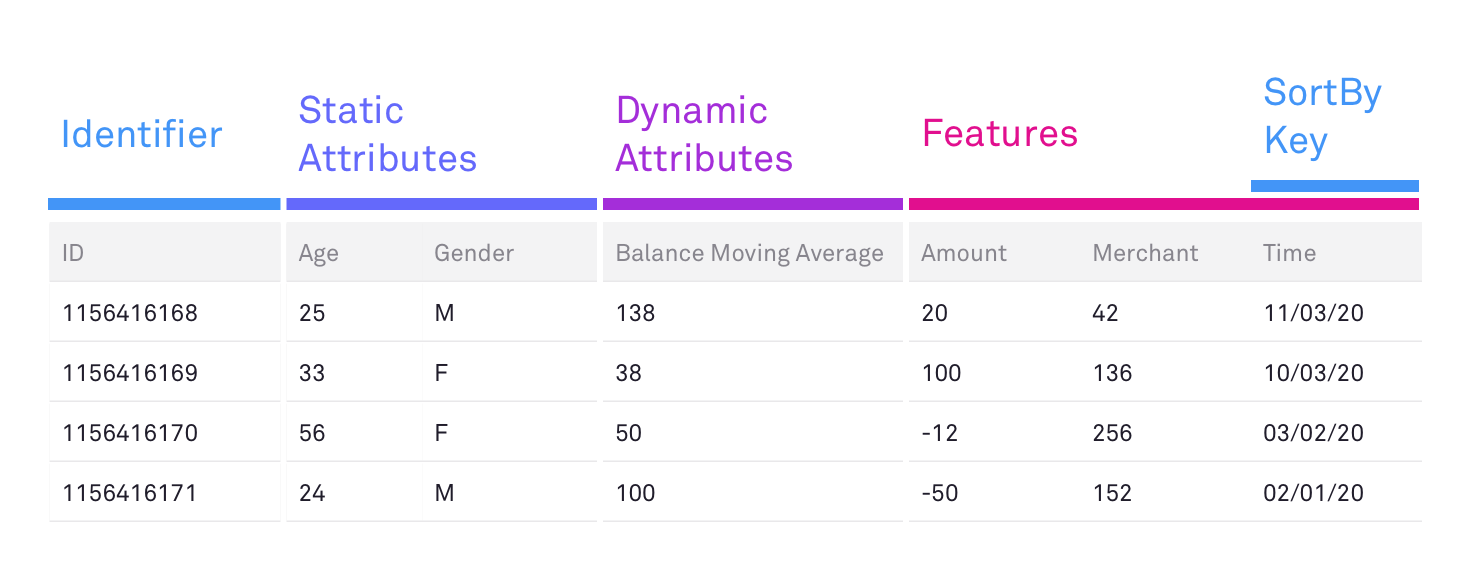
Sequential data is harder to model since:
- Sequences can have a variable length.
- Sequences can have variable time periods between entries (eg bank transactions)
- We need to capture not only dependencies over columns, but also over the rows (normally time).
- This means that synthetic data should capture trends, seasonality effects, and so on, that may exist in the data.
- Synthetic data should also preserve temporal correlations. For instance, when a user buys item X on a given day, they are likely to buy item Y the next day. These correlations may be very long range which makes it hard to model on the synthetic version.
- We need to preserve cumulative effects (total monthly or yearly expenditure on given items).