
Apply Differential Privacy with caution or you could bias your synthetic data

Generative machine learning models trained with Differential Privacy (DP) guarantees are becoming the gold standard for producing and sharing synthetic data in a privacy-preserving manner and are at the core of our technology at Hazy. While in many business use cases privacy might be the greatest concern, applying DP blindly might lead to generating synthetic data with undesirable fairness characteristics. In particular, DP might impact underrepresented subgroups in a dataset that already incur lower utility (in terms of representation or classification accuracy) disproportionately more. For an intuitive and visual introduction to the relationship between DP and fairness in discriminative, rather than generative models please refer to this google blogpost.
Recent studies explore these disproportionate impacts in the light of generative models in detail. The extensive experiments consider three state-of-the-art DP generative models (PrivBayes, DP-WGAN, and PATE-GAN) evaluated on a number of tabular and image datasets from two angles – the size and classification accuracy on subgroups of the data – and a wide range of data imbalance levels and privacy budgets. Here, an underrepresented subgroup could be female, the digit 8, or a less frequent combination of age, sex, and race.
The main research questions and findings could be summarized as:
-
Do DP generative models generate data in similar classes and subgroups proportions to the real data?
No. DP distorts the proportions; there is a stronger disparate effect on the underrepresented classes and subgroups sizes in the synthetic data generated by all DP generative models. Moreover, this effect is dependent on the specific generative model and DP mechanism; e.g., PrivBayes evens the data (Robin Hood effect), while PATE-GAN increases the imbalance (Matthew effect).
-
Does training a classifier on DP synthetic data lead to the same disparate impact on accuracy as training a DP classifier on the real data?
Yes. Underrepresented classes and subgroups suffer bigger and/or more variable classification drops. Furthermore, majority classes with similar characteristics to minority classes could also suffer from a disproportionate drop in utility. However, in some settings, classifiers trained on synthetic data have better accuracy than DP classifiers trained on the real data.
-
Do all DP mechanisms for DP synthetic data behave similarly under different privacy and data imbalance levels?
No. While classifiers trained on data generated by PATE-GAN perform much better than, or on par with, DP-WGAN, we could observe some undesirable behaviors: PATE-GAN might completely fail to learn some subparts of the data with highly imbalanced multiclass data. With low privacy budgets, it could also generate synthetic data with enhanced correlation between the subgroup and the target columns. On the other hand, PrivBayes is the only model that manages to maintain the data utility on a multiclass tabular data.
To visualize some of the main findings above, let’s look at a concrete example. On the graph below, we can see the performance of the DP generative models (PrivBayes, DP-WGAN, and PATE-GAN) trained with various degrees of privacy (called epsilon, the lower the value the higher the privacy guarantee) on the Texas dataset (containing personal information about hospital patients and their discharges; the classification goal is to predict whether a patient stay was shorter or longer than a week). Here, the underrepresented subgroup is the class representing stays longer than a week (being around 25% of the stays shorter than a week).
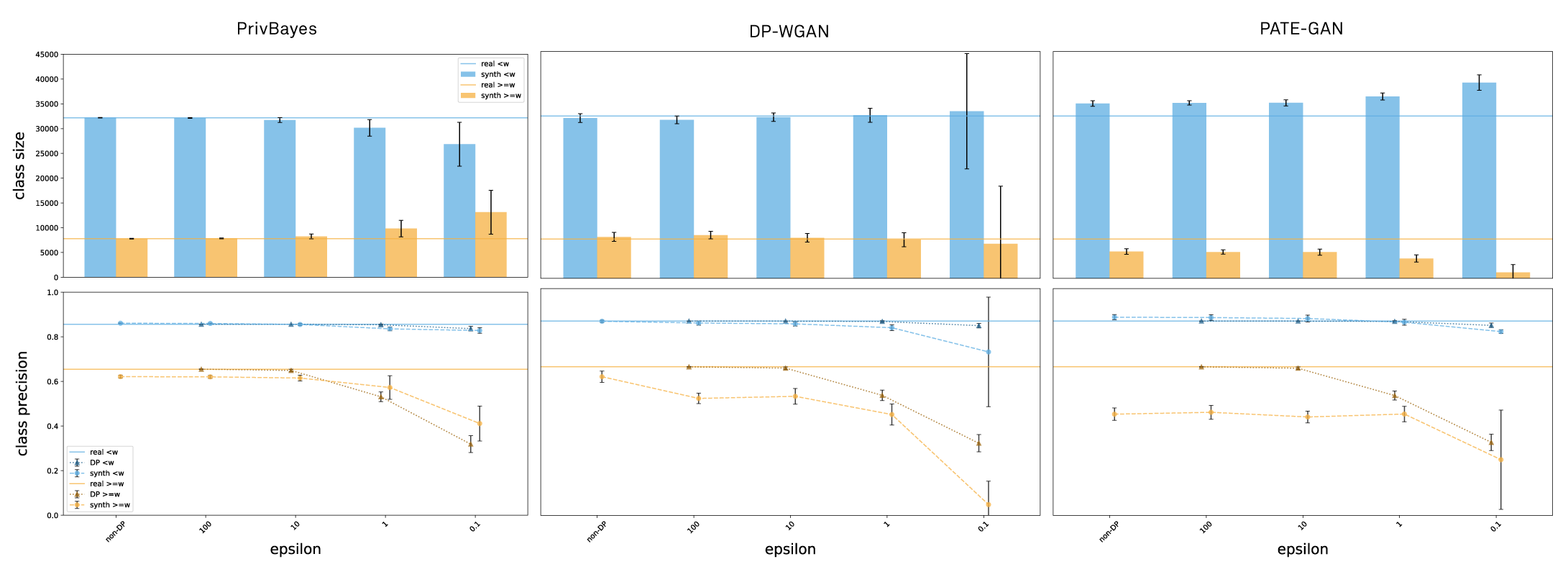
On the top plots, we can clearly see that with decreasing epsilon, PrivBayes reduces the original imbalance of the two classes in the synthetic data, PATE-GAN increases it, while DP-WGAN maintains it best (summarized in 1). When it comes to classification (bottom plots), however, classifiers trained on the synthetic data produced by all generators observe a larger drop on the underrepresented class (stays longer than a week) (summarized in 2). Therefore, the (potentially more vulnerable) patients with longer hospital stays suffer disproportionately more.
As a result, we should be very cautious when analyzing or training a model on synthetic data. Otherwise we risk treating different subpopulations unevenly, which might also lead to unreliable and/or unfair conclusions.
Resources
-
Ganev, G., Oprisanu, B. and De Cristofaro, E., 2021. Robin Hood and Matthew Effects — Differential Privacy Has Disparate Impact on Synthetic Data. https://arxiv.org/abs/2109.11429
-
Ganev, G., 2021. DP-SGD vs PATE: Which Has Less Disparate Impact on GANs?. https://arxiv.org/abs/2111.13617