
How Hazy uses deep learning models to create synthetic datasets

In this piece, we will talk about generative adversarial networks (GANs) — and particularly the Progressive Growing GAN — as a great solution to protecting privacy and data integrity.
At Hazy, we are committed to offering a solution to many of the problems associated with creating datasets that preserve people’s privacy. This is why Hazy creates machine learning-backed synthetic data that retains the same underlying statistics and probability distributions, with none of the privacy risk.
Recently, a Hazy post examined the Uber scooter open dataset and the problem of creating privacy-safe datasets based on public datasets. While thinking about how to apply the Hazy arsenal of GANs to this problem, something occurred to me: what if we try to solve this problem in a purely visual way?
We have the data, and we can just go ahead and feed this into the GAN model, and get a synthetic dataset. However, what if we took the scooter journeys, and drew images between the start and endpoint? What if we then used these images and fed them to a GAN, using just the images, and used this as the dataset to train our GAN?
We are big fans of machine learning and especially deep learning algorithms. The efficacy of neural network models has been constantly shown in previously intractable problem domains such as computer vision and natural language processing. While we continue to lack a mathematical theory to account for its undeniable widespread success, or, as theoretical and computational biologist Terrence Sejnowski recently put it, “the unreasonable effectiveness of deep learning in artificial intelligence,” it remains the state-of-the-art in machine learning.
Introducing Generative Adversarial Networks or GANs
One particular model, generative adversarial networks, or GANs, is of particular interest. Generative adversarial networks consist of two neural nets, the generator and the discriminator, engaged in a computational duel. The generator creates instances of synthetic data. The discriminator is presented with instances of both real and synthetic data, and then has to tell the real from the fake. Eventually, the generator should be able to create synthetic data which looks authentic.
The basic idea of GANs is captured in the following diagram:

The generator is fed a vector of random numbers as input. It then feeds forward, creating synthetic data, for example an image. The discriminator is presented with examples of both real data, from a training dataset, and the synthetic data is produced by the generator. The discriminator has to tell which of these images is real and which is fake — the generator has to try to fool the discriminator by producing increasingly realistic data. The discriminator is the cop, and the generator is the counterfeiter. The ideal is for the counterfeiter to trick the cop.
GANs can be applied to many different problem domains, from creating “realistic” photographs of non-existent people to generating music in given musical styles. One such application is creating aerial photographs, given a street layout.
Here’s a quick Turing Test: Which of the following images is real and which is fake?


As might be appreciated, GANs have a clear role to play in the creation of synthetic datasets.
Many uses of generative adversarial networks involve creating synthetic images, which indirectly lead to the question: Can we approach creating a synthetic dataset in a purely visual way? That is, can we use GANs to create a synthetic dataset of, for example, scooter, taxi or bike journeys, based purely on visual images of such journeys?
This would be analogous to the famous deep learning problem of generating hand-written digits, using the MNIST dataset curated by Yann LeCun. The dataset consists of samples of people’s handwriting, limited to the digits zero to nine. The handwritten digits were scanned and converted to 28x28 black and white images. Generations of different GAN models have been trained and tested on the MNIST dataset’s 80,000 samples of handwriting.



The diagrams above show GANs training on the MNIST dataset. The images were sourced from the terrific and comprehensive collection of GAN models by Hyeonwoo Kang. The leftmost image shows a sample of actual handwriting, the middle image is of a GAN after a certain number of training iterations, and the rightmost image shows the output of a different GAN architecture. GANs can produce very realistic synthetic data.
So, can we use GANs purely in this visual sense? Can they produce virtual, synthetic bike journeys with the same statistical properties as the real thing? Can they do so without access to the specific data points given in the original dataset?
New York City’s Citi Bike share scheme offers content similar to the Uber dataset. It consists of a large number of, in this case, bike journeys, with a start point, a duration, and an end point. The coordinates of the start and end points are each given in latitude and longitude. Here’s an excerpt of the data, read into a pandas dataframe:

We begin by creating a greyscale image of the data, where the intensity of the pixel is proportional to the number of bike journeys passing through that point. So we can create a matrix of bike journeys, starting and stopping at points given by the data and drawing lines between them. Where bike journeys intersect in high traffic areas, we can increase the intensity of the pixel. We will also need a way of converting between coordinates, given in latitude and longitude, and a location in a matrix.
We can find the minimum and maximum latitude of our data, and then we multiply the coordinates by a constant to get the location in a matrix:
min_lat = bike_data["Start Station Latitude"].min()
max_lat = bike_data["Start Station Latitude"].max()
max_lon = bike_data["Start Station Longitude"].max()
min_lon = bike_data["Start Station Longitude"].min()
def latlon_to_pixel(lat, lon, image_shape):
# longitude to pixel conversion (fit data to image)
delta_x = image_shape[1]/(max_lon-min_lon)
# latitude to pixel conversion (maintain aspect ratio)
delta_y = delta_x/np.cos(lat/360*np.pi*2)
pixel_y = (max_lat-lat)*delta_y
pixel_x = (lon-min_lon)*delta_x
return (pixel_y,pixel_x)
def row_to_pixel(row,image_shape):
"""
convert a row (1 trip) to pixel coordinates
of start and end point
"""
start_y, start_x = latlon_to_pixel(row["Start Station Latitude"],
row["Start Station Longitude"], image_shape)
end_y, end_x = latlon_to_pixel(row["End Station Latitude"],
row["End Station Longitude"], image_shape)
xy = (start_x, start_y, end_x, end_y)
return xyThis should give us the bike journeys, converted to locations in a matrix, with the correct aspect ratio. Adding higher intensity for points of intersection between journeys using a convolution filter, we obtain an image like that given below:

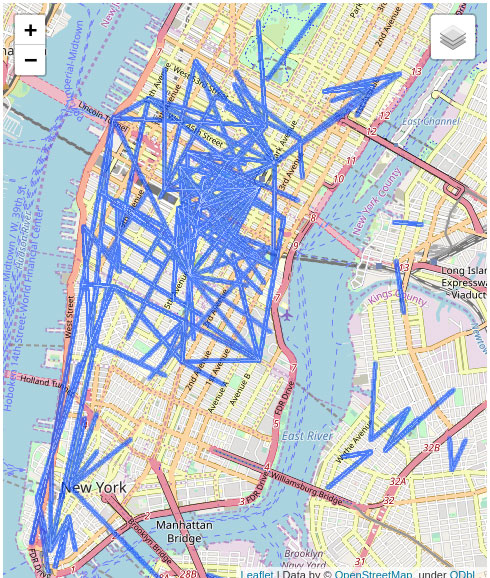
The left-hand-side image shows bike journeys, starting on or after 09:00 a.m., in New York in 2016. The most popular intersections, as noted above, are given a higher intensity. The right-hand-side image shows a detail, a sample of the dataset with bike journeys again shown in blue.
Progressive Growing GAN rises as a useful machine learning model for image training
After some investigation, a Progressive Growing GAN, created and developed by Tero Karras’s team at Cornell University, seemed like a useful model to apply to this task. As its name implies, it grows. Starting with an initial discriminator and generator networks, it begins training on a small, low-resolution image. The algorithm gradually adds further layers of neurons to the model, until a desired output size and resolution is reached.
GANs have been, until recently, limited to fairly small images, like the MNIST handwriting samples given above which are 28x28 and monochrome. Usually the datasets GANs are applied to are only a few hundred pixels in size, sometimes rather less. Generating higher quality, large-scale images was a technical challenge, particularly since deep learning algorithms are computationally expensive. The GANs would have to generate both large-scale images and fine detail.
For these reasons, the discriminator could easily find any problems in details the generator presents to it, leading to low-quality images. Similarly, large images consume a subsequently large amount of memory, whether server RAM or on the GPU.
Karras and his team approached this problem in a novel way, by reducing the initial image and progressively adding layers to the networks. This incremental addition of layers allows networks to initially learn the large-scale structure of the image, and then to focus on increasingly higher-resolution details as they train. Thus, the GAN is capable of creating large, high-quality, photorealistic images of (non-existent!) celebrities.
The Progressive GAN algorithm presents quite an interesting problem: How do we know when to add another layer to the networks? Technically, the new block of layers uses a skip connection to connect the new block to the input of the discriminator or the output of the generator. (See, for example, Orhan and Pitkow in on skip connections and their importance in training deep neural networks.)
The new block is added to the existing input or output layer with a weighting. The weighting controls the influence of the new block and is achieved using a parameter alpha. Alpha starts at zero or a very small number, which is linearly increased to 1.0 over a number of training iterations.
The following diagram, taken from Karras’s paper, illustrates this process:
As the diagram (a) shows, an initial 16x16 generator (G) and discriminator (D) are connected, generator output to discriminator input. In diagram (b), a new layer is added to both networks, along with a weighting for both the 16x16 and 32x32 layers. Eventually, as shown in diagram (c) as alpha approaches 1, the 32x32 takes over the task of providing the output of G, and processing the input of D.
In a little more detail, the generator, initially a 16x16 convolution layer, has to accommodate a new 32x32 layer. The output of the new layer is combined with the original 16x16 layer, which is upsampled using nearest neighbour interpolation. The 16x16, upsampled layer is weighted by (1 - alpha), and the new, 32x32 layer is weighted by alpha. As alpha increases, the contribution of the 32x32 layer also increases. A similar process occurs with the discriminator network.
As an experiment, I sampled a number of bike journeys from the New York City dataset, and trained a Progressive Growing GAN on the images. The images were then downsampled to 32x32 images, so that the amount of detail in each image was small. Here’s a sample of the images:






Now we can set the Progressive Growing GAN working on the dataset, and hopefully obtain some images which resemble the typical sampled bike journeys. All we need to ensure is that the bike journeys’ start and end coordinates are preserved, since these correspond to real bike hire stations in New York. It would be inelegant having somebody finish their journey in the Hudson River.
Since we are only constrained with respect to the start and end stations given in the data, and considering our aim of creating a dataset which discloses no private data, the GAN has considerable freedom to create a dataset. After running for some 3,000 iterations over the data, it produced the samples of synthetic bike ride data given below.



The GANs outputs seem to have preserved the typical shape of a New York bike journey.
GANs are often thought of as one of the more “creative” algorithms in the suite of machine learning techniques. Curious to see how this might manifest itself, I created a dataset by lowering the number of sampled bike journeys to 32 on a 64x64 image, and let the algorithm loose on the data again.
A sample of the results are given below:



These images, in my opinion, reflect this “creative” quality of GANs. They suggest characters in a logographic language like kanji or hieroglyphics. They also look more natural, organic, with softer edges than the original images.
We can now decode the data from the GAN’s output, and translate it back to a dataframe, as can be seen below.
This synthetic bike ride data looks just the same as the original NYC bike hire dataset, and indeed has the same broad statistical properties. The starting and ending locations are, also, all geographically correct, relating to actual bike hire stations in NYC.
With the exception of the start/endpoints, this is utterly synthetic data, generated by a pair of neural networks, role-playing the art forger and the gallery owner out to detect fake Van Goghs. It’s important to note that personal data attributes, including year of birth, gender, and user type, are all synthetic too. That is, the personal information in the original dataset is no longer really real.

Hazy sells privacy. Synthetic datasets created by Hazy’s models have the same statistics, and the same probability distributions, as the original dataset, but without revealing any private data. Hazy’s models create datasets which have the same characteristics, while ensuring that no real data and no personal details appear in the synthetic dataset. This has high utility for data scientists and machine learning engineers, who want to build models without having to go through the entanglements of legislation such as GDPR, and the privacy of the people who contributed to the original dataset in the first place. It also makes it much faster to test out third-parties that want to build on top of your data.
I hope this post has shown that it is possible to create synthetic datasets in a purely visual way, and at the same time preserve privacy.
Oh, and remember the Turing Test above? The two images of the city, one a real aerial photograph, the other synthetic? The fake is the one on the left ...