
Synthetic scooter journeys: How synthetic data and differential privacy work

_This is a comparison post to Gretel’s blog post. We replicated the same task on the same open data set in order to compare the quality of their synthetic data with synthetic data generated by Hazy._
Synthetic data and differential privacy can be abstract and complex if you’re unfamiliar with the mathematics driving them. In this article, we hope to help you understand the value of these two concepts when applied to common geographic data. We use maps and tables to help you visualise the trade-off between noise and differential privacy to find the balance between utility and privacy.
Geographic data is any data or information that’s related to location on Earth. Hazy can take the raw data from this geographic information and turn it into accurate, up-to-date and utterly synthetic data that preserves privacy.
We do this with differential privacy, which is a strong, mathematically provable guarantee of privacy protection. Machine learning and AI algorithms identify statistical patterns and properties of those raw datasets, and we use those to generate completely artificial data that is statistically representative to the raw data. This means that Hazy synthetic data is highly useful without exposing any private or individually identifying data.
For this geographic data use case, the source data is taken from Uber ride shares in Los Angeles over the course of one day. The original format of this public data was the General Bike-share Feed Specification, a standardized data feed for bike share system availability, based on an open-sourced extract.
Source data
| Column | Type | Description | |
|---|---|---|---|
| 0 | Hour | Integer (0-23) | Time of journey |
| 1 | Bike ID | Categorical identifier | Identifier of a bike, rotated to a random string, at minimum, after each trip to protect privacy. |
| 2 | SRC latitude | Floating point number | Journey start WGS84 latitude in decimal degrees |
| 3 | SRC longitude | Floating point number | Journey start WGS84 longitude in decimal degrees |
| 4 | DST latitude | Floating point number | Journey end WGS84 latitude in decimal degrees |
| 5 | DST longitude | Floating point number | Journey end WGS84 longitude in decimal degrees |
The extract contains the hour, bike ID and coordinates where the journey originated and terminated. Most values are numerical but the bike ID requires different handling. The bike ID is treated as a categorical value, similar to assigning a different number for each unique bike ID.
The numerical precision of the position data is high enough to match addresses. It may be feasible to join this data with third party data sources and infer private relations between people. This could place people at risk and exposes the data owner to legal liability.
The promise of synthetic data is to protect the privacy of data subjects while preserving the utility of the data. A possible use for this data is for forecasting periods of high demand. The synthetic data should preserve the aggregate features of the data set without revealing
details of individual journeys.
Sample original sensitive data
| hour | bike_id | src_lat | src_lon | dst_lat | dst_lon | |
|---|---|---|---|---|---|---|
| 14 | 18 | RAC948 | 34.051936 | -118.293878 | 34.061653 | -118.297481 |
| 32 | 4 | LKC371 | 34.010755 | -118.495578 | 33.984336 | -118.443863 |
| 38 | 16 | 32222 | 34.023255 | -118.479798 | 34.017951 | -118.472960 |
| 40 | 18 | AYH051 | 34.000550 | -118.459268 | 33.995906 | -118.476261 |
| 41 | 18 | GVR377 | 34.066710 | -118.278740 | 34.066123 | -118.254270 |
A machine learning model is responsible for capturing the patterns, trends and relationships in the original data. The selection of which model is informed by the use case and depends in part on:
- Training time and resource budget
- Synthetic data quality requirements
- Differential privacy requirements
For this article we'll be using a model based on PrivBayes, which produces good results with minimal or no tuning. Joint distributions can be approximated with this model, given a sufficiently large network degree.
Synthetic data models guarantee differential privacy by adding noise to the captured summary of the original data. The objective is to obscure the presence of any individual row in the original data. Models each have their own way of managing noise and guaranteeing differential privacy.
The amount of noise is determined by the value of the ε (epsilon) parameter, which is set prior to training. Adding more noise provides better privacy, but this makes the synthetic data less similar to the original data. Below is an example of a typical utility / epsilon trade-off graph, used to select an ideal value for ε (epsilon).

Access to the original data is no longer required once a summary is produced. The captured summary is typically very compact, consuming only a fraction of the space. The summary can be transported and stand in as a proxy for the original data. Use cases obtain what would be impossible otherwise:
Exploratory proofs-of-concept
Data science teams are often denied access to potentially valuable, but sensitive data on regulatory grounds. Access to synthetic data unchains the so-called elephant and permits exploration and evaluation of potential value without compromising privacy.
Data amplification
It is possible to produce an arbitrary amount of synthetic data from the captured summary. Large volumes of realistic data is especially useful for load testing, model testing and soak testing.
Comparison of data sets
A model summary is convenient to transport and can traverse jurisdiction boundaries with greater ease. Synthetic data sets can be compared and joined in cases where the volume or ownership of the original data precludes this.
Sample generated synthetic data
| hour | bike_id | src_lat | src_lon | dst_lat | dst_lon | |
|---|---|---|---|---|---|---|
| 0 | 21 | MIF652 | 34.013014 | -118.467514 | 34.019119 | -118.456654 |
| 1 | 17 | CPY498 | 34.076092 | -118.300850 | 34.068953 | -118.299834 |
| 2 | 22 | TAB387 | 34.057146 | -118.294771 | 34.045331 | -118.265588 |
| 3 | 0 | 14245 | 34.028615 | -118.508454 | 34.013603 | -118.495687 |
| 4 | 3 | IMR842 | 34.045581 | -118.306474 | 34.046496 | -118.305277 |
At first glance the sample synthetic journey data looks superficially similar to the original. More extensive similarity measures will be presented below.
Visual comparison
These maps illustrate journeys by joining the start and end coordinates. First illustrating the original data and the second illustrating the Hazy data mapped over that data. Journey starts are coloured violet, ends are cyan (real) or pink (synth) respectively. The accuracy of the positional data clearly aligns with the road network and it is highly likely that addresses could be inferred.
Two major clusters, some smaller clusters and outliers are clearly identifiable. We expect the synthetic journeys to preserve the macro-features of the journeys, while not being precise enough to infer addresses. The maps below can be zoomed to compare features at fine scale.
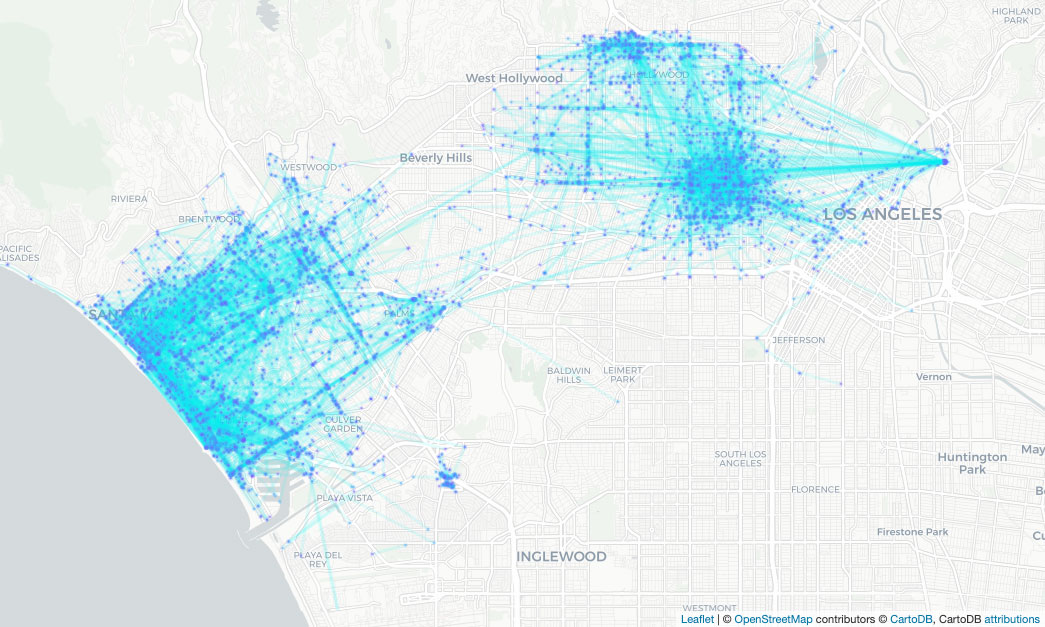
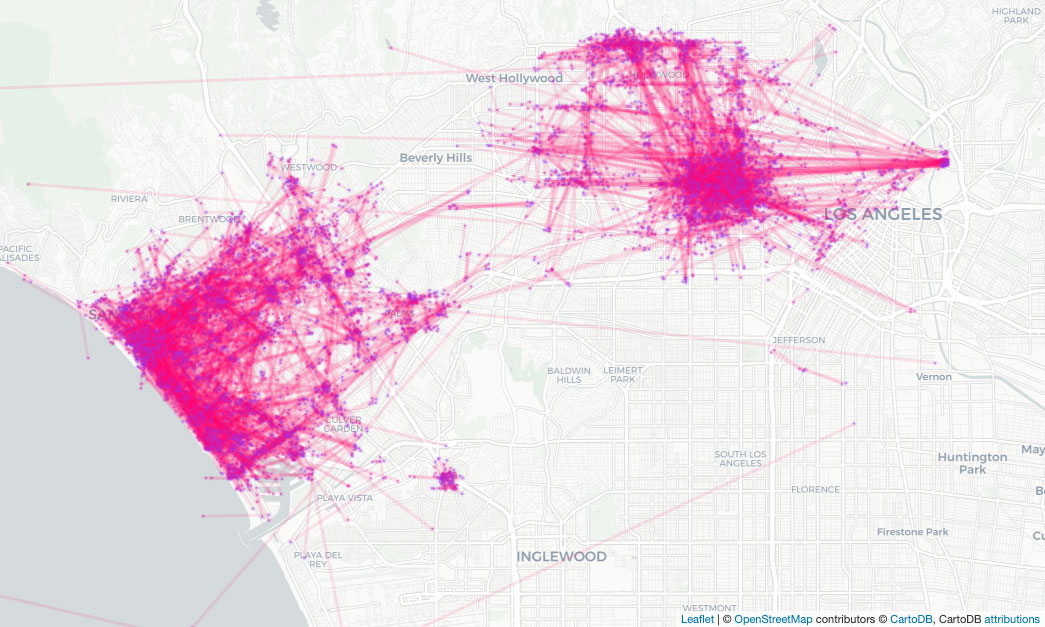
The added noise has generated some obviously infeasible journeys in the ocean. Increasing the value of ε (epsilon) will reduce this, but at the cost of privacy.
The journey start and end positions are clustered in a similar way to the original data. The alignment with the road network is less precise, while capturing the aggregate distribution of positional information.
Generic quality assessment
The synthetic data is subjected to a battery of tests after model training. These tests provide confidence that the synthetic data will be fit for purpose and that ε (epsilon) was not accidentally set too small.
This battery of tests forms part of the core Hazy product. Sign up for a demo to see the full set of tests, including:
- Predictive utility for classification
- Disclosure risk
- Bi-joint distribution similarity
- Feature importance rank relative to many regression algorithms
The next two charts illustrate examples of two such tests.

Marginal distributions are compared for each column of the original and synthetic data. The overlap is 93% in the case of journey starting longitude. The peaks of the distribution correspond to the two major clusters in the map.

The mutual information between pairs of columns is computed for the original and synthetic data. These are compared in the heatmap above, showing a minimum similarity of 0.79 in the mutual information between source latitude and hour.
Journey data specific comparison
The remaining similarities were generated specifically for the journey data.

A comparison between journey distances shows that synthetic data journeys have a similar median. Synthetic journeys shorter than the median are slightly under-represented, while those longer than the median are slightly over-represented.

The following histogram of journey counts by hour illustrates a similar distribution for synthetic and original data. The original data set lacks journeys at 19:00 and so does the synthetic data. The synthetic data has aggregated the original journeys at 12:00 and 13:00 into one larger bucket. A larger value of ε (epsilon) will increase the similarity of the two distributions
The number of journeys recorded per bike illustrates the differences between the synthetic and original data. The number of bikes making a single journey differs by a third. There are two options if a divergence compromises the utility of the data:
Adjusting the utility / privacy trade-off
Increasing the value of ε (epsilon) will reduce the amount of noise in the model and improve the similarity.
Model parameters
The model that was used in this illustration has tunable parameters that improves accuracy, but at the cost of longer training time, greater memory requirements and a larger model summary.