
Multi-table synthetic data

Many of the use-cases served by Hazy can be accommodated with a single-table model. Two examples are a single table of personal details to be used for testing of data processing systems, or to be used for customer segmentation. Hazy can create a private, synthetic replica of the personal details table. Testing processing systems and training a segmentation model using the synthetic data avoids the hazards arising from potentially sensitive information in the original source data.
But many real world datasets for machine learning and test use cases, data is stored in several related tables. Maintaining the relations between tables is a challenge when recreating synthetic replicas of tables, because some details must correlate across tables. For example, one table containing customer details and another containing account details might be related via unique identifiers. The cross-table relation may contain important statistical information that will be lost if tables are recreated independently.

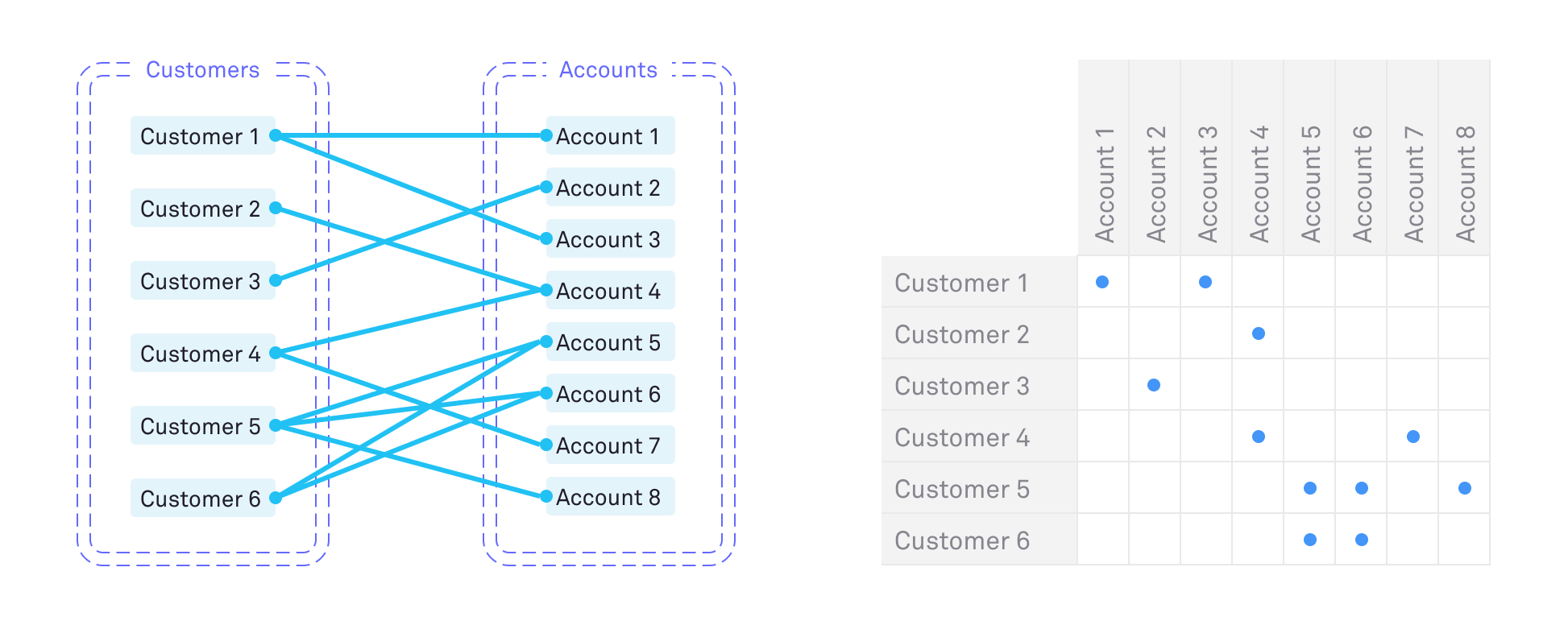
The multi-table model
Hazy has therefore implemented a differentially private multi-table model capable of synthesising arbitrary sets of related tables. The implementation is based on a novel generation procedure that synthesises table relationships separately and then conditionally generates the table contents. This allows not only for accurate replicas of the tables to be recreated with strong privacy guarantees, but also to preserve the mutual information across the tables. One-to-one, one-to-many and many-to-many relationships are supported.
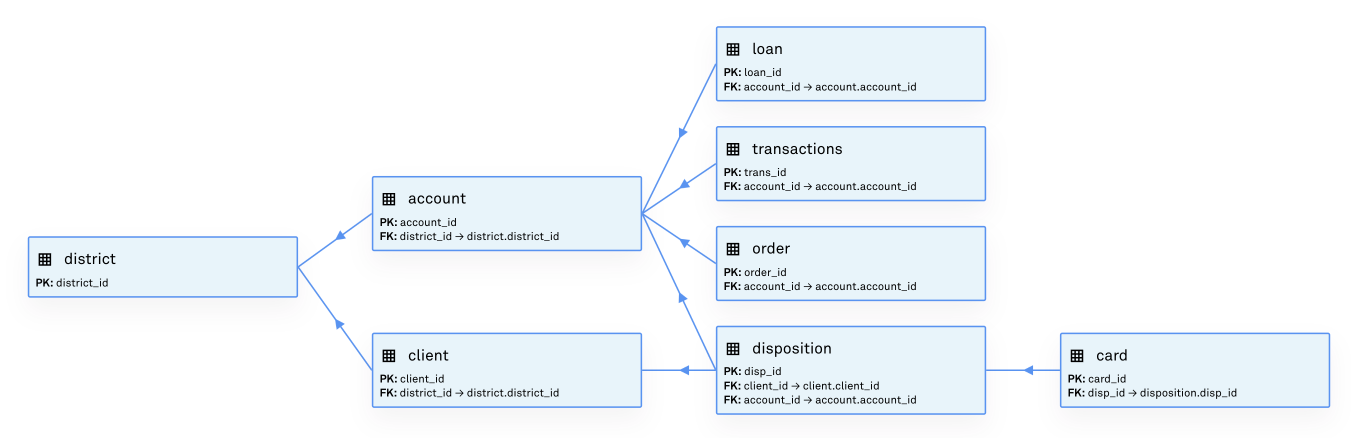
Metrics
Multi-table datasets call for a specialised way of measuring the information between tables. This is important for testing use cases to ensure the relative volume of data matches the original source, but also for machine learning and AI use cases where statistical signals must be preserved when tables are joined.
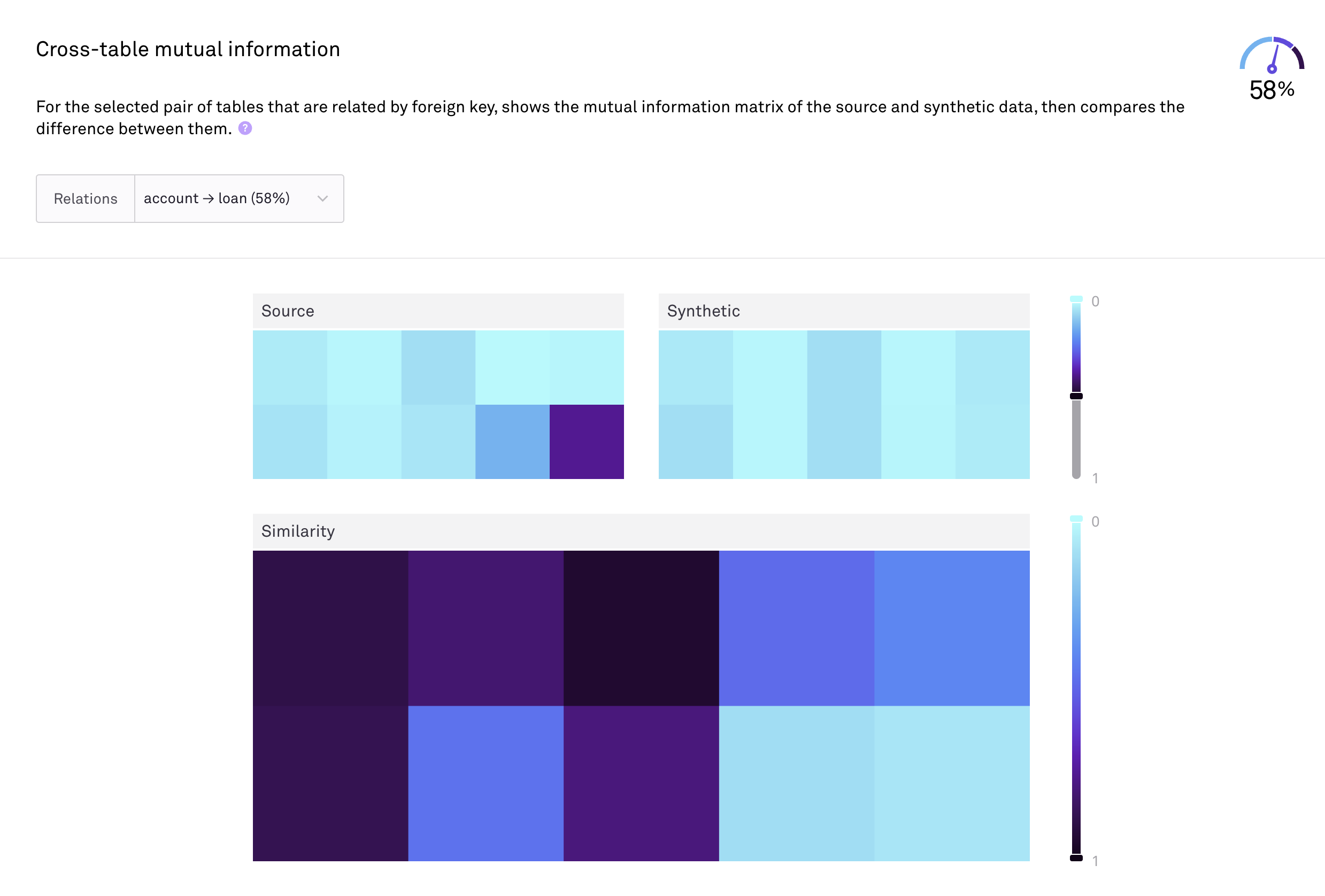
The Hazy evaluation suite contains dedicated multi-table data evaluation metrics. The Cross Table Mutual Information metric compares the mutual information of columns in tables related by a foreign key. Graph similarity metrics are used to make sure the structure of synthetic foreign key relations are similar to their counterparts in the original data source.
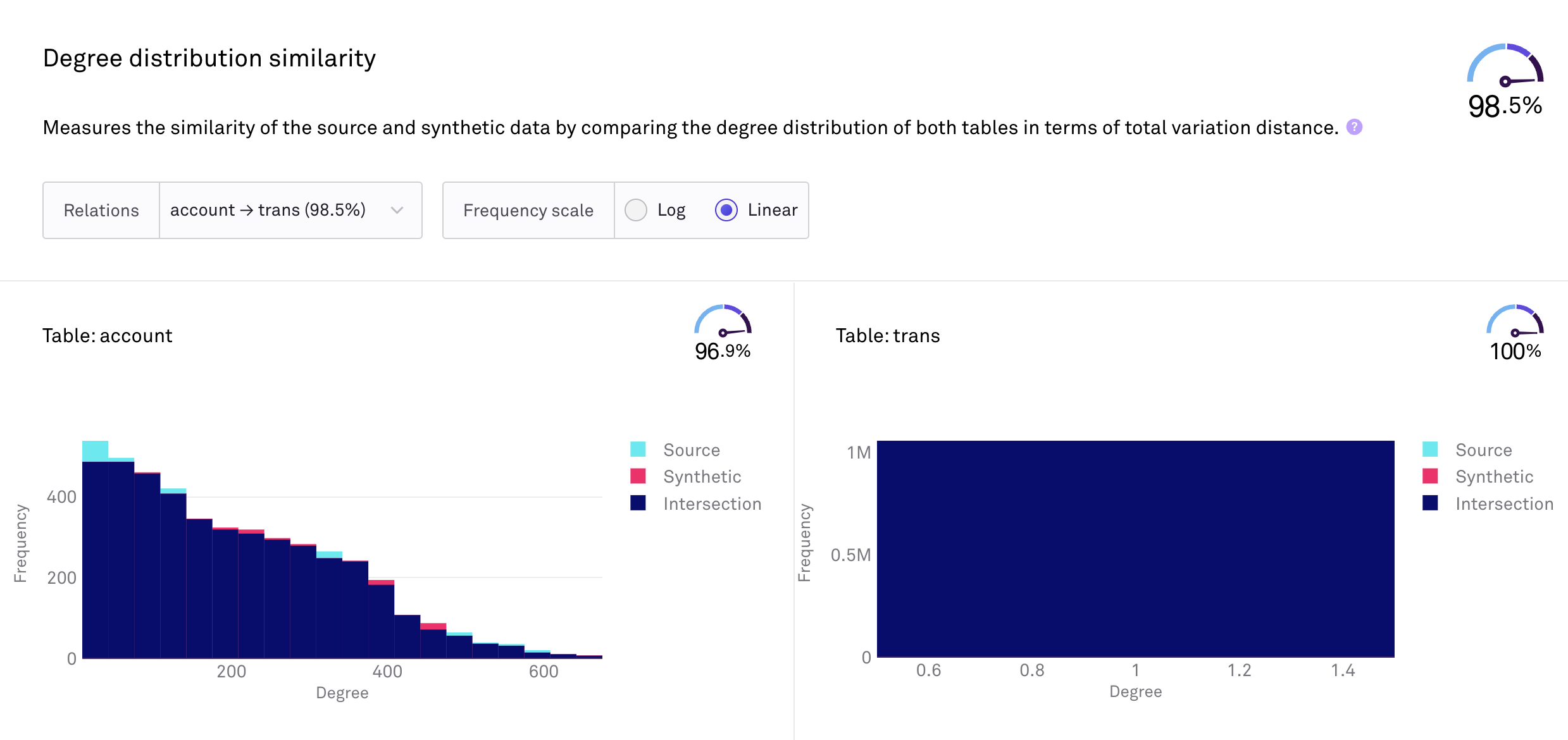
Comparison
We have used the MovieLens 100K dataset to compare the Hazy platform with the Synthetic Data Vault (SDV) hierarchical model. While SDV is the closest competitor with a comparable feature, SDV does not support conditioning on multiple related tables and has limited support for many-to-many relationships. Hazy outperformed SDV by a significant margin when comparing the similarity of tables and the multi-table -specific metrics described earlier. This is not unexpected, given the limitations of the SDV model.
Please get in touch if you would like more details or see a demonstration of how the Hazy platform can be used to create synthetic versions of your data.